Taking CosmosDB and pushing to Neo4j
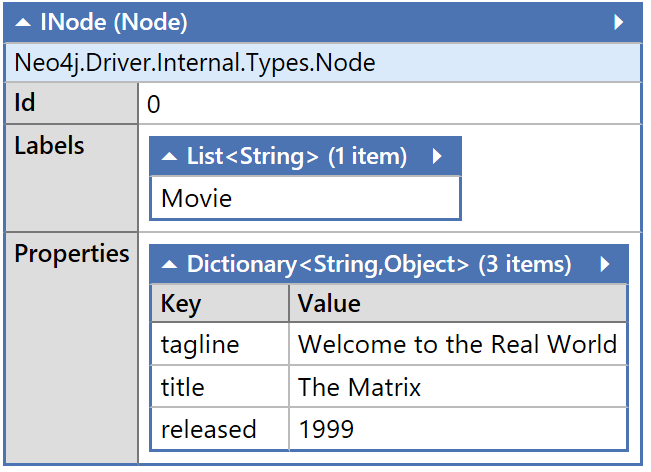
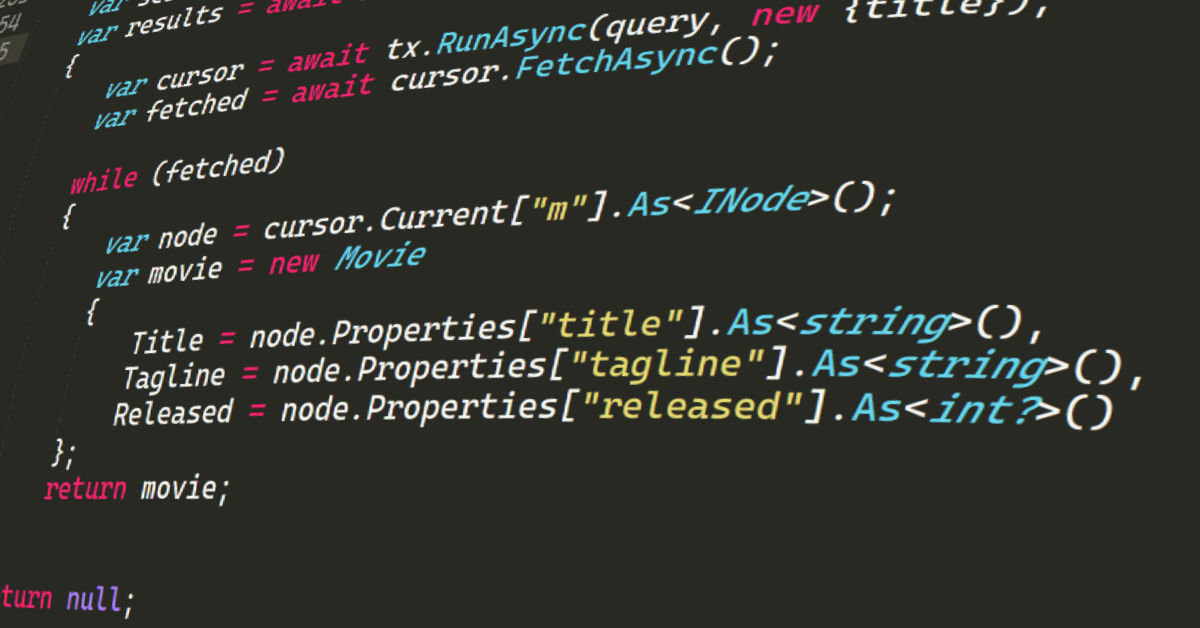
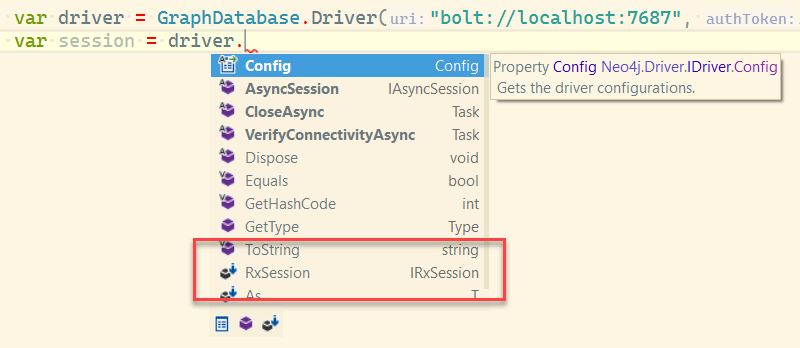
TL; DR.The project reads data from a CosmosDB instance, and inserts it into Neo4j – there’s no clever ‘re-modeling’ – just a simple push in. Have a look at the project site for more info! Technology moves fast, and decisions of the past may not be great for solutions of the future, it might be…