Taking CosmosDB and pushing to Neo4j

TL; DR.
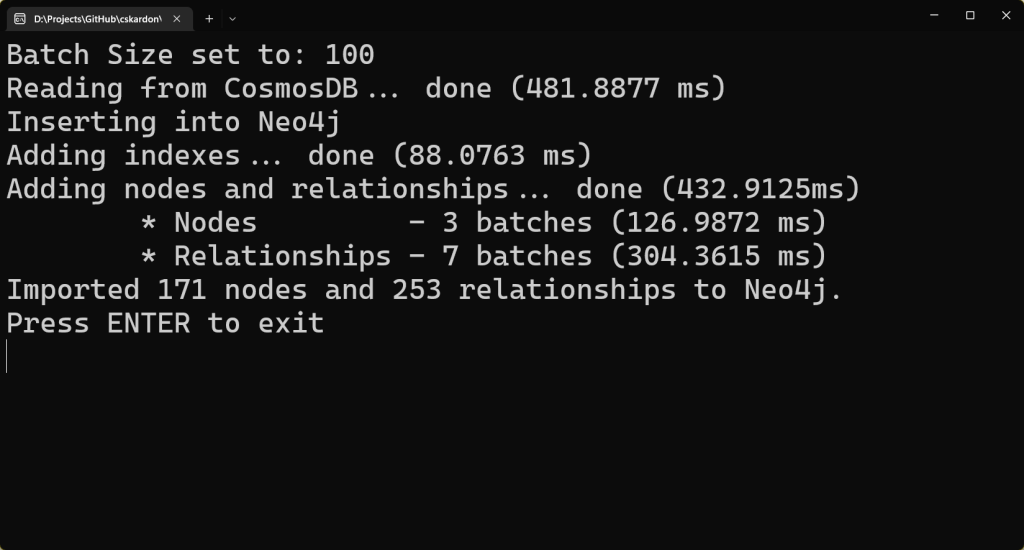
The project reads data from a CosmosDB instance, and inserts it into Neo4j – there’s no clever ‘re-modeling’ – just a simple push in. Have a look at the project site for more info!
Technology moves fast, and decisions of the past may not be great for solutions of the future, it might be something like the language you’ve chosen, or more complicated like the stack. Sometimes you catch these early enough, and it’s not a big deal, sometimes you’ve put a lot of effort in, and so you stick with what you’ve got.
You might also be evaluating technologies at the beginning of a project, and you’ve invested a lot of time into one solution – and the prospect of moving that data across to another is onerous at best.
This post is about how you can tackle that last problem, or indeed the ‘existing’ solution one, provided we’re talking about ComosDB and Neo4j.
CosmosDB is Microsoft’s Azure hosted database, it has a few APIs – but, as we’re talking about this in the context of Neo4j, we’re interested in the Gremlin API which sits on top, providing a Graph endpoint.
What we want to do is take a graph that’s already been implemented in Cosmos – and translate it into Neo4j. Whilst we can interact with Cosmos in a variety of ways – we’re going to be using Gremlin – as that will give us the best view of the graph.
First off, it’s worth noting that Cosmos implements Gremlin – but not necessarily the latest version – which means we might have to do things in ways which are not ideal, but we work with what we have.
General App Layout
There are 3 main things to look at, with lots of supporting files:
Program.cs- This is where the program runs from – getting the mappings, and executing the correct order, as you would expect.
CosmosDb.cs- The interaction with Cosmos – so – the read side of things
Neo4j.cs- The interaction with Neo4j – so – as expected – the write side of things
Most of the program side of things is pretty self-explanatory – there’s a few checks to see what’s in the Cosmos DB, whether your Neo4j one is empty, and check on the mappings.
Mappings?
Neo4j and CosmosDB both have the concept of Labels for Nodes (albeit with some differences), and Types for Relationships (Cosmos calls them labels as well). When we read from Cosmos we can supply a Mappings file, this tells the app how to insert the data into Neo4j. For example, you might have a label called ‘Actor’ in Cosmos, that you want to call ‘Person’ in Neo4j.
The structure of the file is a simple JSON file:
{
"Nodes": [
{
"Cosmos": "Actor",
"Neo4j": "Person"
}
],
"Relationships": [
{
"Cosmos": "Acted",
"Neo4j": "ACTED_IN"
},
{
"Cosmos": "Watched",
"Neo4j": "REVIEWED"
}
]
}
Which you pass in via a command line parameter. If you choose not to pass in a file, the app will do a straight 1:1 conversion – i.e. ‘Actor’ would be ‘Actor’ in Neo4j.
Nodes / Vertices
The first task is to read in the Nodes from Cosmos – to do that we go through each label type in Cosmos and pull the nodes out. There is no concept of paging we can use to be able to pull smaller amounts of data out, so I have implemented a rough divisor of the nodes using GUIDs as IDs (based on this idea). We can get 36 pages by looking for IDs that start with 0, then 1 all the way through to z. The downside is if you’re not using GUID IDs (which is the default Cosmos way) – or you have such a big dataset that 36 isn’t going to cut it. These are problems that are solvable either by a) increasing the number of pages the GUID Paginator can handle or b) providing your own IPaginator to do the paging for you.
Anyhews!
We end up running the following Gremlin against CosmosDB:
g.V()
.hasLabel("Actor")
.has("id", gte("0"))
.has("id", lt("2"))This gets us all the Nodes with the label Actor where the id property starts with 0 or 1. We’ll end up generating one of these queries per page – so the way this is done, 18 pages.
One thing to note is that this is on a per label basis, so if you have 10 labels, and pages set up to be 30, you will potentially generate 300 pages. Some of those might have no data, some might have lots, it’s a very rough approximation for pages.
Once we execute the queries – we get back a set of dynamic objects – because we can’t know what the actual properties are. We then parse these into CosmosNode objects, with an important property called PropertiesAsDictionary which we use to insert data into Neo4j.
We would read the Relationships next, but for the purposes of this post, we’ll talk about inserting the nodes into Neo4j first.
The nodes are passed into the Neo4j instance in batches, this helps with memory use, and also performance – it’s better to do one call instead of 4000, even if you’re just taking into consideration the extra network traffic.
To do this, we read the data coming from Cosmos into Lists that are the size of the batches we’ve configured – all by label as with everything else. So – we have a List<CosmosNode> and we pass that to our Neo4j Client to UNWIND. Cypher wise – this is easy:
UNWIND $nodes AS node
MERGE (n:Person {CosmosId: node.id})
SET n += node.PropertiesAsDictionaryThere are a few things which will likely need to be changed – the use of node.id as a MERGEable identifier – may not be accurate – but for the purposes of this – it works well. The += of the Dictionary puts the properties straight into Neo4j. This has been tested with numbers and strings, but things like arrays have yet to be tested – so – if you have trouble around that, do please raise an issue!
Another note!
Prior to inserting the nodes, a set of indexes is added to the Neo4j database on the property CosmosId for each of the labels being ingested – this increases the performance of inserting both the nodes and the relationships.
The nodes are all ingested first, this means the subsequent Relationship ingestion should have all the nodes already in the database, and we can potentially look at ways to parallelise the node ingestion in the future.
Relationships / Edges
At this stage we’ve got the Nodes relatively sorted – next up is getting the Relationships – and it won’t surprise anyone to know that the procedure is pretty much the same – Gremlin to get the relationships, Cypher to ingest them.
Our Gremlin looks almost the same, all we do is switch out the V() for E():
g.E()
.hasLabel("ACTED_IN")
.has("id", gte("0"))
.has("id", lt("2"))The main difference is what we parse it into – which is a CosmosRelationship – which contains the Id of the Incoming Node (inV) and Outgoing Node (outV). We can use this (with batching in the same way as with nodes) to UNWIND the relationships and push them into our Neo4j database.
UNWIND $relationships AS rel
MATCH (inN {CosmosId: rel.inV})
MATCH (outN {CosmosId: rel.outV})
MERGE (inN)-[r:ACTED_IN]->(outN)
SET r += rel.propertiesWe don’t need to use a Dictionary in the same way as with nodes, as it seems (and I might be wrong on this) that Cosmos doesn’t handle the same range of properties on a relationship as on a Node.
There are areas for improvement here – I’m not using the Labels for the Nodes, (inN and outN) which I really should – and that would make generating the relationships not just based on type but also in/out labels – to allow the UNWIND to do its job properly.
You can also see the MATCH statements there use the CosmosId property to match on, which is why the indexes are created.
Potential Issues
As with anything like this, there are potential issues, which will be looked at over time, or indeed you can create an issue / PR for them:
- Memory usage – it pulls everything from Cosmos before inserting – with the pagination in place – there could be ways to implement a more measured ‘page-by-page’ approach.
- Restartability – if you cancelled it halfway through – you can restart – as the queries are idempotent – but it will redo the already imported Nodes / Rels.
- Property types – I’ve only tested with limited types, I’m not sure how things like arrays etc will be handled.
- Doesn’t create indexes on other properties
- Doesn’t map property names (i.e. ‘fname’ to ‘firstName’, for example)
Overall
This aims to help users of Cosmos either migrate to Neo4j, or indeed try Neo4j on an existing dataset that they know rather than a ‘demo’ set – with hopefully minimal effort.