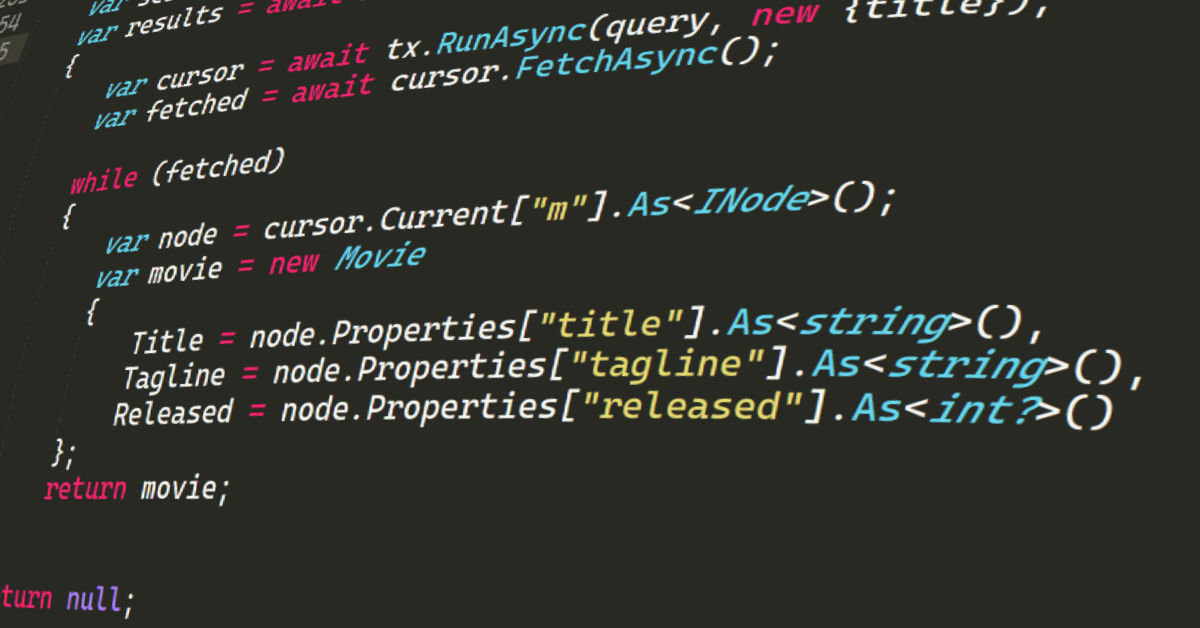
Using Neo4j.Driver? Now you can EXTEND it!
Hot on the heels of Neo4jClient 4.0.0, I was doing some work with the Neo4j.Driver (the official client for Neo4j), and in doing so, I realised I was writing a lot of boiler plate code.…
Hot on the heels of Neo4jClient 4.0.0, I was doing some work with the Neo4j.Driver (the official client for Neo4j), and in doing so, I realised I was writing a lot of boiler plate code.…

After what probably seems like ages to you (and indeed me) Neo4jClient 4.0 has finally left the pre-release stages and is now in a stable release. Being a major version change, that means there are…
Yes! That’s the TL;DR; out of the way 🙂 The slightly longer version is that you need to use the 1.4.0.0 version of the Neo4j SSIS Components. This is the main change to the components…
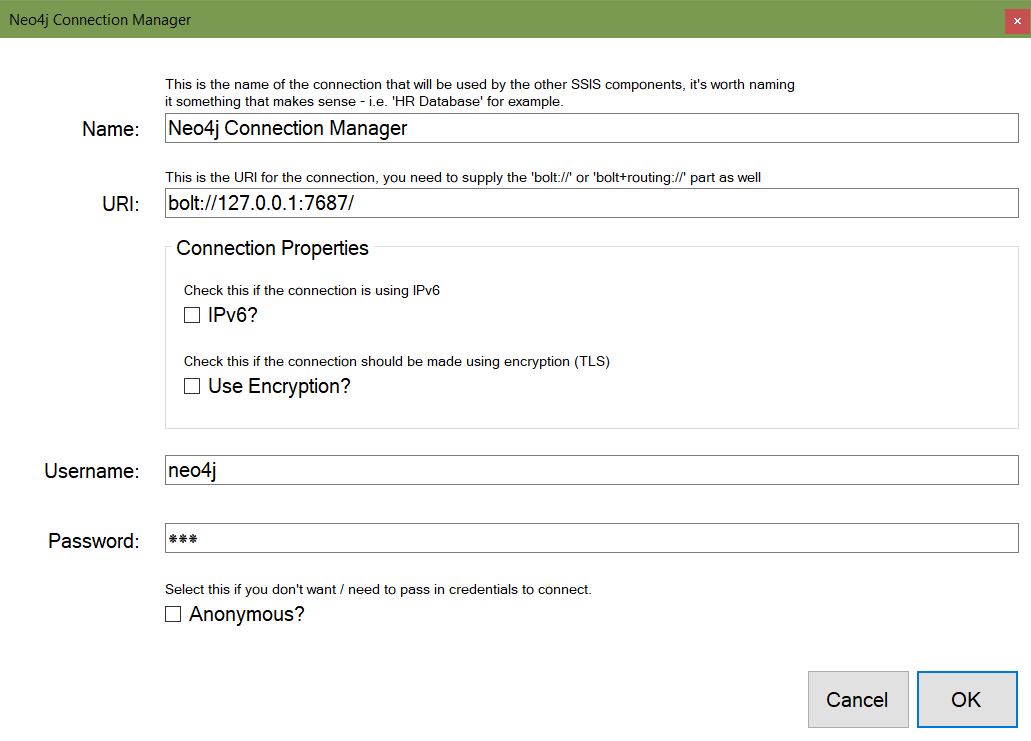
I’ve not written about the SSIS components for a bit, but I have been working on them – adding things, improving things. One area that was always very basic was the Connection interface. Or lack…

Another day, another ETL tool, this time Apache NiFi which is described as: An easy to use, powerful, and reliable system to process and distribute data. I’ve used SSIS and Kettle in the past, so…
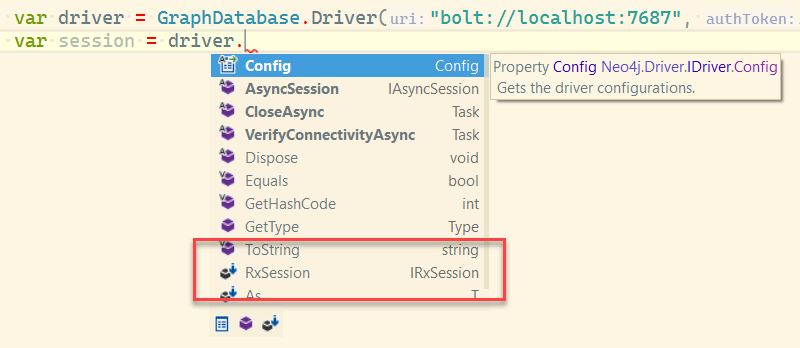
Version 4.0 of Neo4j is being actively worked on, and aside from the new things in the database itself, the drivers get an update as well – and one of the big updates is the…
Last week, Anabranch released version 1.1 of the tools for Neo4j – which included a very welcome addition to the toolset – being able to pull data from a Neo4j instance. After doing the demo…

That’s right everyone! We’re going from Neo4j this time, and this is a new release, the old version (1.0.0.0) didn’t have a ‘Neo4j as a Source’ component, 1.1.0.0 does. In the last post we took…

In what is rapidly becoming a series of posts – we look into another of the components in the Anabranch SSIS Components for Neo4j package. The last post looked at using the “Execute Cypher Task”…

Last Friday, Anabranch released the first beta version of it’s connector to Neo4j from SSIS. Aside from a post saying that it existed, I didn’t go into detail, so this is going to be a…